
E-mails plus intelligents, affaires plus rapides. Marquage, analyse et réponse automatique aux demandes de devis, devis, commandes, etc. — instantanément.
Base de données vectorielle. Exploitez l'intelligence non structurée de l'aviation.
juillet 15, 2025
Les bases de données vectorielles indexent des vecteurs d'intégration de grande dimension pour permettre la recherche sémantique sur des données non structurées, contrairement aux bases de données relationnelles ou documentaires traditionnelles qui utilisent des correspondances exactes sur des mots-clés. Au lieu de tables ou de documents, les bases de données vectorielles gèrent des vecteurs numériques denses (souvent de 768 à 3072 dimensions) représentant la sémantique d'un texte ou d'une image. Au moment de la requête, la base de données trouve les voisins les plus proches d'un vecteur de requête à l'aide d'algorithmes de recherche par voisin le plus proche approximatif (ANN). Par exemple, un index basé sur des graphes comme Hierarchical Navigable Small Worlds (HNSW) construit des graphes de proximité en couches : une petite couche supérieure pour la recherche grossière et des couches inférieures plus larges pour l'affinement (voir figure ci-dessous). La recherche « saute » le long de ces couches, se localisant rapidement sur un cluster avant de rechercher de manière exhaustive les voisins locaux. Cela permet de concilier le rappel (recherche des voisins les plus proches) et la latence : l'augmentation du paramètre de recherche HNSW (efSearch) augmente le rappel au détriment du temps de requête.
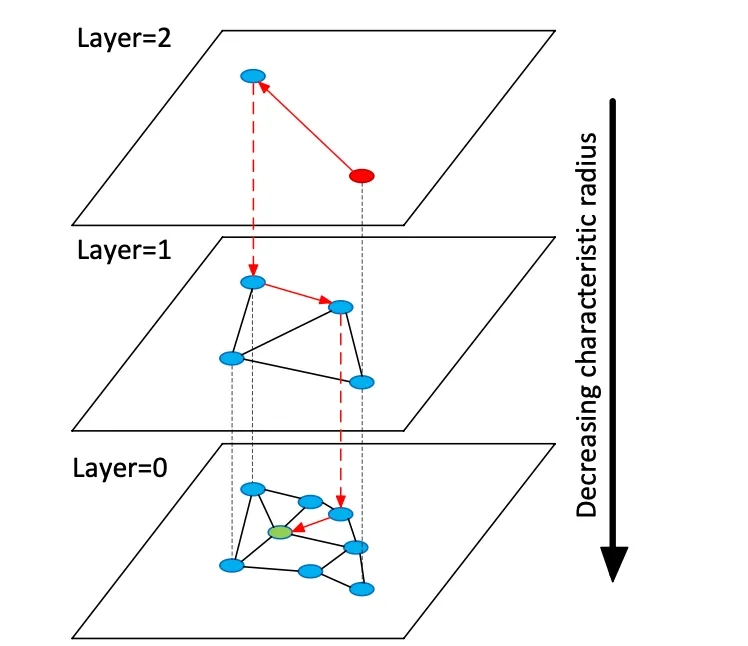
Figure : Graphique de recherche HNSW ANN – les vecteurs sont organisés en couches pour accélérer les requêtes de plus proche voisin (adapté de l’explication des ensembles de vecteurs Redis de Devmy).
Contrairement à la recherche exacte dans les tables relationnelles, la recherche vectorielle permet de capturer le sens : les requêtes trouvent des éléments sémantiquement similaires, et pas seulement des correspondances exactes de mots clés. Pour les données aéronautiques (par exemple, les manuels ou les journaux de réparation), cela signifie que les ingénieurs peuvent récupérer du contenu pertinent même si la formulation diffère. Les distances vectorielles (cosinus, produit scalaire ou euclidienne) quantifient la similarité. Lorsque les plongements sont normalisés, la similarité cosinus et le produit scalaire donnent des classements équivalents. En pratique, on normalise généralement les vecteurs et on utilise la similarité cosinus comme mesure de pertinence. Les principaux compromis concernent le rappel et la latence : des indices plus grands et des paramètres de recherche plus élevés améliorent le rappel mais augmentent la latence. Les bases de données vectorielles fournissent des indices ajustables (HNSW, IVF, flat scan) pour équilibrer vitesse et précision.
Modèles d'intégration
Les modèles d'intégration modernes convertissent le texte (ou d'autres données) en vecteurs. Parmi les principaux modèles, on trouve text-embedding-3-large d'OpenAI, embed-multilingual-v3 de Cohere, les modèles Gemini/BGE de Google, les familles E5 et GTE de Meta, ainsi que de nombreux modèles HuggingFace (par exemple, les variantes de Sentence-BERT). Ces modèles diffèrent en termes de dimensionnalité, de couverture de données et de coût d'inférence. Par exemple, text-embedding-3-large d'OpenAI produit des vecteurs de 3 072 dimensions, nettement plus grands que la version précédente d'Ada-002 (1 536 D). Les modèles v3 de Cohere produisent généralement des vecteurs de 1 024 D (versions anglaises ou multilingues) ou moins (par exemple, versions « light » de 384 D). Les modèles E5-large et GTE-large de Meta produisent également des intégrations de 1 024 D, tandis que leurs variantes de base ou « small » produisent 768 D ou 384 D. Les intégrations Vertex-AI de Google incluent des modèles textuels 768D et un grand modèle « gemini-embedding-001 » 3072D. En général, des dimensions plus élevées améliorent souvent la fidélité sémantique, mais nécessitent davantage de stockage et de calcul : e5-base (768D) a indexé un ensemble de données plus de deux fois plus rapidement qu'ada-002 (1536D) lors d'un benchmark.
Les modèles d'intégration varient également en fonction des données d'entraînement et du multilinguisme. Les API d'intégration d'OpenAI et de Cohere sont propriétaires (avec des coûts et des limites d'utilisation associés), tandis que les modèles E5/GTE de Meta et de nombreux modèles HuggingFace sont open source (sous licence Apache). Les modèles E5 et GTE prennent en charge plus de 50 langues, tout comme les modèles multilingues v3 de Cohere. Cette couverture multilingue est précieuse pour la documentation aéronautique internationale. L'adaptation au domaine est essentielle pour les vocabulaires spécialisés (par exemple, la langue des chapitres ATA, la nomenclature des pièces). Prêts à l'emploi, ces modèles sont entraînés sur du texte web et des corpus courants ; ils peuvent ne pas capturer parfaitement le jargon aéronautique. Les équipes devraient envisager d'affiner ou d'utiliser des adaptateurs sur les journaux ou les manuels de maintenance. En pratique, les systèmes d'entreprise commencent souvent par des intégrations générales solides (comme OpenAI ou E5), puis affinent le texte spécifique au domaine.
Du point de vue des performances, la latence des modèles varie. Les modèles plus petits (par exemple, E5-base-768) sont plus rapides à l'inférence, tandis que les grands modèles propriétaires (3072D d'OpenAI) sont plus lents et peuvent n'autoriser qu'une seule requête à la fois. Si le matériel sur site est limité, des modèles plus petits ou quantifiés peuvent être utilisés. Les licences sont importantes : OpenAI et Cohere facturent par requête et ont des politiques d'utilisation, tandis que les modèles ouverts comme E5/GTE ou BGE de Google (ouvert via VertexAI avec des quotas) évitent les coûts d'API. En résumé, toute base de données vectorielle peut ingérer des intégrations de n'importe lequel de ces modèles, mais les architectes doivent prendre en compte la dimensionnalité de l'intégration, le coût, la prise en charge multilingue et l'adéquation au domaine lors de la sélection des modèles pour les données aéronautiques.
Types de bases de données vectorielles
Il existe une gamme de systèmes de bases de données vectorielles, allant des bibliothèques légères aux plates-formes à part entière :
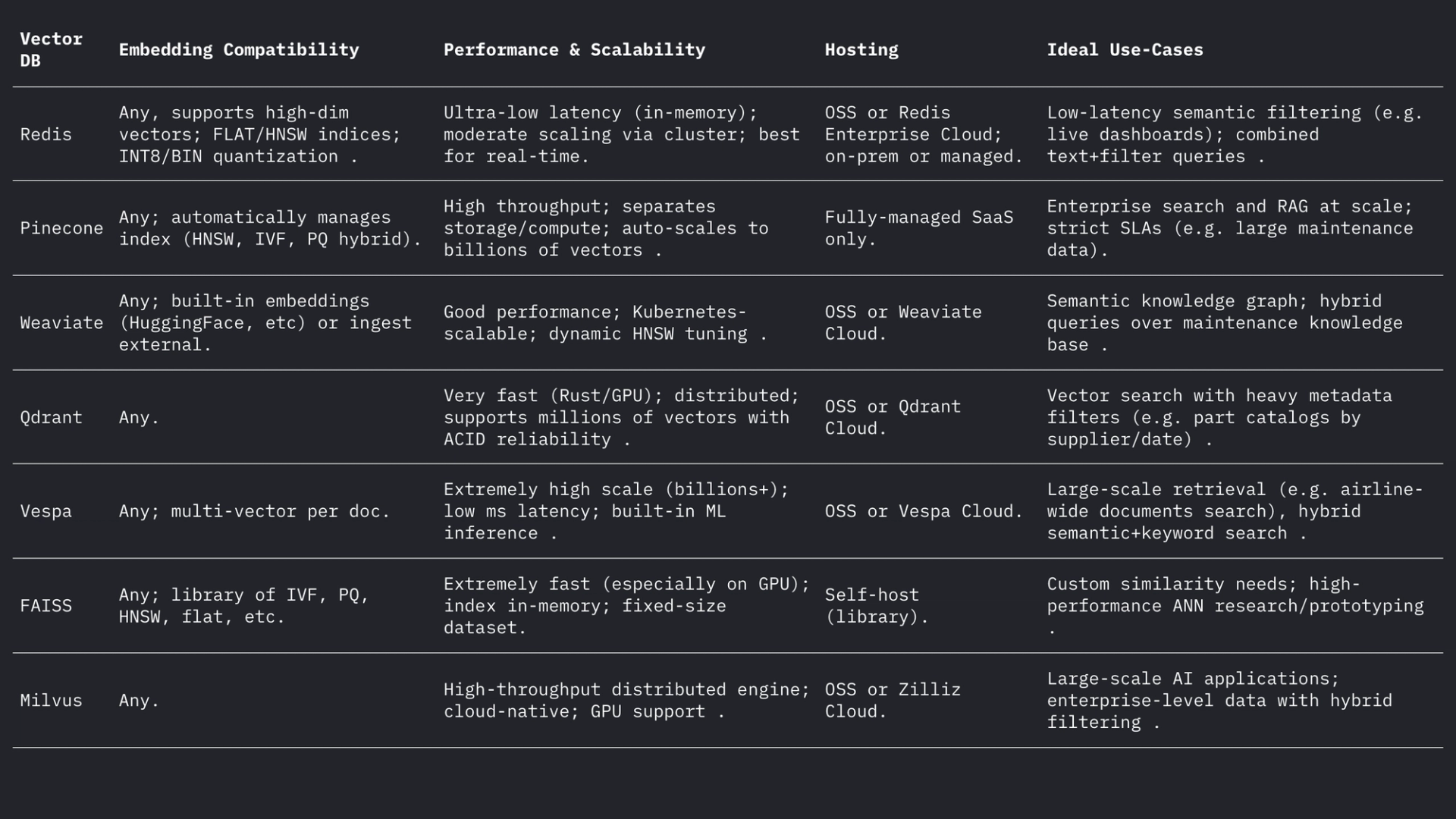
- Redis (Ensembles de vecteurs) – Redis est un magasin clé-valeur en mémoire doté d'un module d'index vectoriel. Il prend en charge les index FLAT (force brute exacte) et HNSW. Les ensembles de vecteurs Redis permettent des mises à jour dynamiques uniques : les graphiques HNSW sont gérés de manière bidirectionnelle, ce qui permet d'ajouter ou de supprimer des vecteurs à la volée avec effet immédiat. Redis prend en charge la quantification (8 bits ou binaire) pour réduire la mémoire (jusqu'à 4 × à 32 ×) avec une perte de précision minimale. Il offre également un filtrage hybride : les vecteurs peuvent être stockés avec des balises texte ou des champs numériques et filtrés (par exemple, .year > 2020) dans la même requête. En tant que moteur en mémoire, Redis offre une latence ultra-faible au détriment de la RAM. Il s'adapte horizontalement grâce au clustering, bien que la taille des clusters soit généralement inférieure à celle des plateformes vectorielles dédiées. Redis est disponible en open source ou via Redis Enterprise Cloud.
- Pinecone – Un service cloud de recherche vectorielle entièrement géré. Pinecone isole toute l'infrastructure : il sépare le stockage du calcul et s'adapte à des milliards de vecteurs tout en maintenant des temps de requête rapides. Il gère automatiquement les index en arrière-plan (combinant HNSW, IVF, PQ, etc.) pour des performances optimales. Le compromis réside dans le coût et l'opacité : Pinecone est facile à utiliser (sans opérations), mais plus cher qu'un OSS. Il excelle dans les charges de travail à haut débit et soumises à des SLA, prenant en charge les requêtes hybrides (mots-clés + vecteurs) et les fonctionnalités d'entreprise. Pinecone est idéal pour les équipes qui recherchent une évolutivité et une fiabilité de niveau entreprise sans avoir à gérer de serveurs.
- Weaviate – Une base de données vectorielle open source centrée sur les graphes (également proposée en service managé). Weaviate permet une structuration riche en schémas et graphes de connaissances, ainsi que des vecteurs. Il propose une API GraphQL pour combiner la recherche vectorielle sémantique aux requêtes traditionnelles (récupération hybride). Weaviate utilise principalement des index HNSW (et peut utiliser des index plats pour les petits ensembles de données). Il ajuste automatiquement les paramètres de recherche ou autorise l'indexation asynchrone pour un meilleur débit. Grâce à ses modules d'apprentissage profond, Weaviate peut même générer des vecteurs (par exemple, via des modèles HuggingFace). Il est évolutif via Kubernetes et des clusters cloud ou sur site. Les points forts de Weaviate résident dans sa recherche hybride sémantique et symbolique et sa flexibilité dans la modélisation des données ; il est adapté lorsque les relations (par exemple, les hiérarchies pièce-avion) sont aussi importantes que la similarité vectorielle.
- Qdrant – Un moteur de recherche vectoriel open source en Rust. Qdrant offre un index ANN hautes performances avec un filtrage de métadonnées enrichi. Il prend en charge les index HNSW avec mise à l'échelle automatique dynamique et fournit une API HTTP. Qdrant met notamment l'accent sur un filtrage rigoureux et une fiabilité optimale : il prend en charge le déploiement distribué, les transactions ACID et l'accélération GPU. Il est très performant sur les grands ensembles de données et affiche un taux de rappel élevé. Qdrant Cloud simplifie le déploiement, tout en étant auto-hébergé. Cela fait de Qdrant un choix judicieux lorsque vous avez besoin de combiner similarité vectorielle et filtres structurés (par exemple, pour rechercher uniquement dans certains modèles d'avion ou plages de dates).
- Vespa – Un moteur de recherche et d'analyse open source, développé par Yahoo. Vespa intègre de manière unique la recherche vectorielle à la recherche classique par index inversé. Il peut gérer des milliards de vecteurs avec un débit extrême : la plateforme annonce la prise en charge de milliers de QPS avec des latences inférieures à 100 ms sur des volumes de données importants. Vespa prend en charge la recherche multi-vecteurs par document et la recherche hybride (sémantique + mot-clé). Son indexation ANN inclut HNSW (et de nouvelles variantes comme HNSW-IF qui combinent le filtrage inversé de fichiers). En tant que serveur d'applications complet, Vespa prend également en charge les modèles de classement personnalisés et les pipelines d'inférence ML. Il est donc parfaitement adapté aux applications de recherche critiques à grande échelle (par exemple, les portails de recherche de compagnies aériennes) où l'évolutivité et la pertinence hybride sont essentielles. Vespa peut être autogéré ou utilisé via Vespa Cloud.
- FAISS – Une bibliothèque de recherche de Meta pour la recherche de similarité. FAISS n'est pas une base de données autonome, mais un ensemble d'index hautement optimisés (Flat, IVF, PQ, HNSW, etc.) fonctionnant sur CPU/GPU. Elle offre une vitesse exceptionnelle (notamment avec les GPU) et une flexibilité exceptionnelle : presque toutes les mesures de distance ou méthodes d'indexation peuvent être utilisées. Cependant, FAISS n'inclut pas de moteur de stockage/requête ni de filtrage des métadonnées ; vous devez l'intégrer à votre propre système. Elle est particulièrement adaptée aux besoins de performances maximales et de contrôle des algorithmes d'indexation. Par exemple, FAISS est largement utilisé en vision par ordinateur et en recherche en ML, où le rappel et la rapidité sont primordiaux et la taille des données est fixe. Dans l'aéronautique, FAISS pourrait soutenir un outil de recherche personnalisé pour les intégrations de très grande dimension (par exemple, la reconnaissance de pièces à partir d'images), mais cela nécessite une architecture adaptée.
- Milvus – Une base de données vectorielle open source populaire, conçue pour les charges de travail à grande échelle. Milvus propose des modes autonome et distribué, prenant en charge des milliards de vecteurs avec une forte cohérence. Elle offre plusieurs types d'index (HNSW, IVF, Annoy, etc.) et métriques (cosinus, L2, etc.), ainsi qu'une recherche hybride via un filtrage scalaire. Milvus est accéléré par GPU et cloud-native (intégration avec Kubernetes). Elle inclut des fonctionnalités d'entreprise comme les snapshots et le chiffrement, et est activement développée par Zilliz. L'architecture de Milvus est conçue pour l'évolutivité et la performance, ce qui la rend idéale pour les applications gourmandes en données, telles que l'analyse d'archives volumineuses de manuels ou de journaux de capteurs. Zilliz propose également Milvus Cloud pour l'hébergement géré.
Chacun de ces systèmes gère les vecteurs et les filtres différemment, mais tous prennent en charge les distances L2, les produits scalaires (points) et les cosinus (souvent en stockant des vecteurs normalisés). Le forum de Weaviate indique qu'il peut même stocker des vecteurs jusqu'à 65 535 dimensions, bien au-delà des tailles d'intégration classiques, démontrant ainsi la flexibilité des moteurs modernes. En résumé :
Cas d'utilisation dans l'aviation
Recherche sémantique : La maintenance aéronautique implique de vastes collections de manuels, de bulletins de service et de documents réglementaires. Un système de recherche vectorielle permet aux ingénieurs d'effectuer des requêtes en langage naturel (voire vocales) et de récupérer les passages ou documents pertinents de manière sémantique. Par exemple, au lieu d'une recherche par mot-clé sur « fuite d'huile moteur », une recherche par intégration peut trouver des paragraphes de bulletin décrivant « fuite de liquide hydraulique » si leur contexte est similaire. Comme l'a démontré Infosys/AWS, le stockage de chaque document technique sous forme de vecteurs permet aux agents LLM de répondre aux requêtes de maintenance en récupérant les documents les plus pertinents dans le référentiel.
Correspondance floue des pièces : Les pièces aéronautiques présentent souvent des identifiants complexes (NSN ou numéros de pièce) et des noms descriptifs qui varient selon les fournisseurs. L'intégration vectorielle des descriptions de pièces, voire des numéros de pièce (traités comme du texte), peut révéler des quasi-doublons que la correspondance basée sur des règles ne détecte pas. Dans d'autres domaines, l'intégration de mots a été utilisée pour établir une correspondance floue sémantique des noms ; de même, l'intégration de descripteurs de pièces permet de lier une pièce à sa description la plus proche dans les catalogues des fournisseurs, même si l'orthographe ou les codes diffèrent. Cela pourrait unifier l'inventaire provenant de sources multiples.
Classification et regroupement des journaux : Les journaux de réparation et de pannes sont généralement au format texte libre. Les modèles d'intégration permettent de convertir les entrées de journal en vecteurs, et le regroupement de ces vecteurs permet de regrouper automatiquement les schémas de pannes similaires. Par exemple, le framework « HELP » regroupe les journaux système de streaming selon leurs intégrations afin de découvrir les modèles de journaux récurrents. Dans l'aéronautique, un regroupement analogue pourrait identifier les modes de défaillance courants ou catégoriser les entrées de maintenance imprévues sans étiquettes prédéfinies, permettant ainsi l'analyse des problèmes fréquents (par exemple, le regroupement des incidents de « vibrations étranges »). Ce regroupement sémantique non supervisé facilite l'analyse des tendances et la prévision de la charge de travail.
Récupération conversationnelle (RAG) : Les intégrations sous-tendent les systèmes de récupération-génération augmentée (RAG) qui alimentent les chatbots sur documents. Un exemple de chatbot PDF illustre l'architecture : extraire le texte des manuels, le segmenter, intégrer chaque segment et le stocker dans un magasin vectoriel (comme FAISS). À l'exécution, chaque requête utilisateur est intégrée et utilisée pour récupérer les k segments les plus pertinents via l'index vectoriel. Ces segments constituent le contexte permettant à un LLM de répondre à la question. Dans l'aviation, un pipeline RAG permet à un technicien de « converser » avec le jumeau numérique de l'avion : par exemple, en demandant « Quelle est la procédure de remplacement du contacteur de chauffage Pitot ? », et d'obtenir une réponse précise issue des manuels OEM.
Indexation prédictive des pannes : Les historiques de maintenance décrivent les pannes et leurs correctifs. Ces descriptions pourraient être indexées sous forme de vecteurs afin de comparer la description d'un nouvel incident à des cas antérieurs similaires. Des recherches en maintenance prédictive ont montré que le calcul de la similarité sémantique des textes de panne à l'aide d'intégrations de transformateurs (avec similarité cosinus ou Pearson) permet de regrouper efficacement les pannes apparentées. En pratique, lorsqu'un mécanicien consigne une nouvelle description de panne, le système pourrait récupérer les incidents antérieurs présentant une forte similarité d'intégration afin de suggérer des causes profondes ou des vérifications probables, réalisant ainsi une « prédiction » efficace basée sur la proximité dans l'espace d'intégration.
Considérations pratiques sur la conception
Dimensionnalité de l'intégration : Les intégrations de plus grande dimension capturent davantage de nuances, mais coûtent plus cher en stockage et en calcul. Les choix courants sont 768, 1024, 1536 ou 3072 dimensions. Par exemple, les modèles plus volumineux d'OpenAI utilisent des dimensions de 1536 à 3072, tandis que les modèles E5/GTE de base de Meta utilisent 768 ou 1024. Lors d'une expérience pilote, l'indexation du même corpus a pris 2,4 fois plus de temps avec des intégrations de 1536D qu'avec 768D. Ainsi, si le débit et la latence sont critiques (par exemple, filtrage sur l'appareil de centaines de requêtes/s), 768D ou 1024D peuvent suffire. Si l'objectif est un rappel maximal (et que le matériel le permet), des dimensions plus importantes sont acceptables. Pour l'aviation, on peut commencer avec 1024D (équilibré) et tester des modèles plus petits ou plus grands sur des tâches de récupération de données de domaine.
Métrique de distance : Le choix du cosinus (ou produit scalaire normalisé) ou de la distance euclidienne brute dépend de l'intégration. La plupart des intégrations textuelles modernes sont comparées par similarité cosinus. Par exemple, Tekgöz et al. ont constaté que les métriques cosinus/Pearson offraient la meilleure similarité pour les descriptions de défaillances. Redis et d'autres systèmes prennent en charge la spécification explicite de « COSinus » (normalisation des vecteurs en arrière-plan), tandis que de nombreux systèmes utilisent le produit scalaire sur des vecteurs prénormalisés. En pratique, cosinus et produit scalaire sont équivalents si les intégrations sont normalisées. La distance euclidienne est moins courante pour le texte, mais conceptuellement similaire lorsque les vecteurs sont sur une sphère. Recommandation : utiliser le cosinus pour les intégrations textuelles.
Métadonnées et structuration hybride : Il est important de stocker les intégrations vectorielles avec les métadonnées structurées (modèle d'avion, chapitre ATA, date, numéro de pièce, etc.) pour affiner la recherche. Tous les stockages vectoriels modernes permettent d'attacher des métadonnées à chaque vecteur. Par exemple, les ensembles de vecteurs Redis permettent de filtrer par attributs JSON dans la même requête (par exemple, WHERE aircraft_model = 'A320' AND ATA = '21'). Qdrant offre un filtrage booléen puissant pour affiner les résultats vectoriels par métadonnées. Lors de la conception du schéma, définissez les champs de métadonnées (par exemple, modèle, ata, date, numéro de pièce) et indexez-les normalement tout en marquant le champ de texte comme VECTEUR. Dans les requêtes hybrides, le système applique d'abord le filtre de métadonnées (ou le combine via une pénalité de score), puis recherche uniquement les voisins les plus proches dans le sous-ensemble, améliorant ainsi la précision. Assurez-vous que les filtres critiques (par exemple, numéro de queue d'avion ou plage horaire) sont appliqués aux champs scalaires indexés pour exploiter le filtrage de la base de données.
Réglage de la latence et du débit : les paramètres d'index ANN doivent être ajustés en fonction de la latence cible. Pour les requêtes HNSW, augmenter le paramètre efSearch augmente le rappel, mais augmente linéairement le temps de requête. Une approche pratique consiste à comparer le rappel et la latence sur un ensemble de données : commencez par un ef faible pour la vitesse, puis augmentez jusqu'à atteindre un plateau de rappel. Weaviate prend même en charge un « ef dynamique » qui adapte ef au nombre de résultats souhaité. Pour les charges de travail par lots, il est possible d'utiliser des index FLAT (exacts) pour maximiser la précision, tandis que pour les requêtes en temps réel de plusieurs dizaines de millisecondes, HNSW ou IVF avec des paramètres ajustés est préférable. La quantification (8 bits, quantification produit) est un autre levier : par exemple, les paramètres Q8 vs BIN de Redis réduisent considérablement la mémoire et accélèrent la recherche, au prix d'une légère baisse de précision.
Mises à jour d'index : Si vos données changent fréquemment (nouvelles entrées de journal ou mises à jour manuelles), choisissez des systèmes prenant en charge l'indexation dynamique. L'implémentation HNSW de Redis permet des insertions et des suppressions à la volée sans reconstruire l'index. Weaviate peut mettre à jour HNSW de manière asynchrone (les écritures ne bloquent donc pas les lectures). D'autres outils, comme FAISS, nécessitent généralement une réindexation ; utilisez-les donc pour les corpus principalement statiques. Prévoyez une réindexation si de nouveaux manuels arrivent ou si des journaux quotidiens doivent être ajoutés. Dans de nombreux systèmes aéronautiques, les manuels changent lentement, mais les journaux quotidiens/entrées de répartition arrivent ; les approches hybrides (écriture de nouveaux vecteurs dans un index « chaud » pendant une journée et fusion la nuit) peuvent donc fonctionner.
Résumé
Les bases de données vectorielles et les modèles d'intégration permettent une intelligence sémantique riche sur les données aéronautiques. Les intégrations de haute qualité (par exemple, les modèles 768-3072D) traduisent les manuels, les journaux de bord et les descriptions de pièces en vecteurs consultables, tandis que les bases de données vectorielles spécialisées (Redis, Pinecone, Weaviate, Qdrant, Vespa, FAISS, Milvus) fournissent les index RNA et le filtrage nécessaires à grande échelle. Le tableau ci-dessus compare les principales fonctionnalités : Redis et Qdrant excellent en faible latence avec filtrage ; Pinecone et Milvus brillent à grande échelle ; Weaviate et Vespa prennent en charge les requêtes hybrides (graphe + vecteur) ; FAISS offre des performances optimales pour les pipelines personnalisés. Les choix d'intégration (modèle, dimension, normalisation) et le réglage des index (paramètres HNSW, quantification) doivent être équilibrés entre rappel et rapidité. Ensemble, ces technologies permettent aux équipes ML de l’aviation de créer des outils avancés (interfaces utilisateur de recherche sémantique, chatbots de maintenance, analyses prédictives) qui convertissent les journaux et les manuels non structurés en informations exploitables.
Tendances en matière de maintenance aéronautique susceptibles de prendre de l'ampleur dans des circonstances incertaines
Les avions restent en service plus longtemps, les chaînes d'approvisionnement sont une véritable poudrière et la technologie évolue du jour au lendemain. Découvrez les tendances de maintenance qui gagnent du terrain et leurs implications pour les exploitants qui cherchent à maintenir leur rentabilité.

July 13, 2025
Comment ePlaneAI révolutionne l'approvisionnement aéronautique grâce à la blockchain
Les pièces contrefaites clouent au sol les flottes. ePlaneAI change cela grâce à l'approvisionnement basé sur la blockchain, apportant traçabilité, confiance et automatisation à l'aviation.

July 8, 2025
Comment utiliser les jumeaux numériques pour la maintenance prédictive dans l'aviation
Les jumeaux numériques sont là pour aider les compagnies aériennes à réduire les temps d'arrêt, à diminuer les coûts de maintenance et à améliorer la sécurité. Voici comment la maintenance prédictive prend son essor dans l'innovation aéronautique.

July 3, 2025
Comment la réduction du poids des avions réduit les coûts de carburant (et quelles pièces peuvent être remplacées pour réduire le poids)
Faire du poids. Découvrez comment les compagnies aériennes réduisent le poids de leurs appareils pour réduire leur encombrement et leurs émissions de CO₂, en supprimant un siège, un chariot et un connecteur à la fois.
