
Correo más inteligente, negocios más rápidos. Etiqueta, analiza y responde automáticamente a solicitudes, cotizaciones, pedidos y más — al instante.
Vector DB. Desbloquea la inteligencia no estructurada de la aviación.
julio 15, 2025
Las bases de datos vectoriales indexan vectores de incrustación de alta dimensión para permitir la búsqueda semántica sobre datos no estructurados, a diferencia de los almacenes relacionales o de documentos tradicionales que utilizan coincidencias exactas en palabras clave. En lugar de tablas o documentos, los almacenes vectoriales gestionan vectores numéricos densos (a menudo de 768 a 3072 dimensiones) que representan la semántica de texto o imagen. En el momento de la consulta, la base de datos encuentra vecinos más cercanos a un vector de consulta utilizando algoritmos de búsqueda de vecino más cercano aproximado (RNA). Por ejemplo, un índice basado en grafos como Hierarchical Navigable Small Worlds (HNSW) construye grafos de proximidad en capas: una pequeña capa superior para la búsqueda gruesa y capas inferiores más grandes para el refinamiento (véase la figura siguiente). La búsqueda "salta" por estas capas, localizándose rápidamente en un clúster antes de buscar exhaustivamente a los vecinos locales. Esto compensa la recuperación (encontrar los verdaderos vecinos más cercanos) con la latencia: aumentar el parámetro de búsqueda HNSW (efSearch) aumenta la recuperación a costa de un mayor tiempo de consulta.
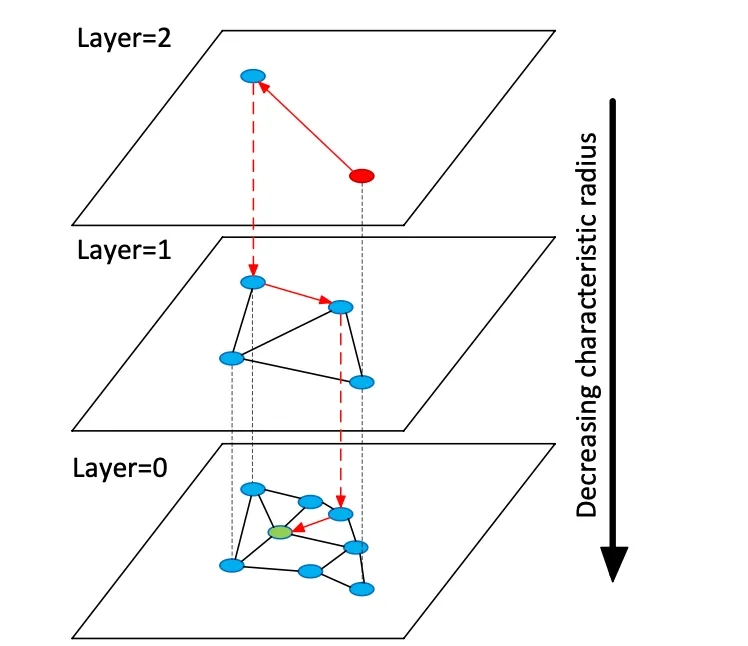
Figura: Gráfico de búsqueda de ANN HNSW: los vectores se organizan en capas para acelerar las consultas al vecino más cercano (adaptado de la explicación de los conjuntos de vectores Redis de Devmy).
A diferencia de la búsqueda exacta en tablas relacionales, la búsqueda vectorial puede capturar el significado: las consultas encuentran elementos semánticamente similares, no solo coincidencias exactas de palabras clave. Para datos de aviación (p. ej., manuales o registros de reparación), esto significa que los ingenieros pueden recuperar contenido relevante incluso si la redacción difiere. Las distancias vectoriales (coseno, producto escalar o euclidiana) cuantifican la similitud. Cuando se normalizan las incrustaciones, la similitud del coseno y el producto escalar producen clasificaciones equivalentes. En la práctica, uno comúnmente normaliza los vectores y usa la similitud del coseno como la métrica de relevancia. Las compensaciones clave incluyen recuperación vs. latencia: índices más grandes y parámetros de búsqueda más altos mejoran la recuperación pero aumentan la latencia. Las bases de datos vectoriales proporcionan índices ajustables (HNSW, IVF, escaneo plano) para equilibrar la velocidad versus la precisión.
Modelos de incrustación
Los modelos de incrustación modernos convierten texto (u otros datos) en vectores. Entre los modelos líderes se incluyen text-embedding-3-large de OpenAI, embed-multilingual-v3 de Cohere, los modelos Gemini/BGE de Google, las familias E5 y GTE de Meta y muchos modelos HuggingFace (p. ej., variantes de Sentence-BERT). Estos modelos difieren en dimensionalidad, cobertura de datos y coste de inferencia. Por ejemplo, text-embedding-3-large de OpenAI produce vectores de 3072 dimensiones, significativamente más grandes que el anterior Ada-002 (1536D). Los modelos v3 de Cohere suelen generar 1024D (inglés o multilingüe) o más pequeños (p. ej., versiones "light" de 384D). E5-large y GTE-large de Meta también producen incrustaciones de 1024D, mientras que sus variantes base o "pequeñas" producen 768D o 384D. Las incrustaciones Vertex-AI de Google incluyen modelos de texto 768D y un modelo grande "gemini-embedding-001" 3072D. En general, las dimensiones mayores suelen mejorar la fidelidad semántica, pero requieren más almacenamiento y procesamiento: e5-base (768D) indexó un conjunto de datos más del doble de rápido que ada-002 (1536D) en una prueba de rendimiento.
Los modelos de incrustación también varían según los datos de entrenamiento y el multilingüismo. Las API de incrustación de OpenAI y Cohere son propietarias (con costos asociados y límites de uso), mientras que E5/GTE de Meta y muchos modelos de HuggingFace son de código abierto (con licencia Apache). Los modelos E5 y GTE admiten más de 50 idiomas, al igual que los modelos multilingües v3 de Cohere. Esta cobertura multilingüe es valiosa para la documentación de aviación internacional. La adaptación del dominio es fundamental para vocabularios especializados (p. ej., lenguaje de capítulos de ATA, nomenclatura de piezas). De fábrica, estos modelos se entrenan con texto web y corpus comunes; es posible que no capturen perfectamente la jerga de la aviación. Los equipos deben considerar realizar ajustes o usar adaptadores en los registros de mantenimiento o manuales. En la práctica, los sistemas empresariales a menudo comienzan con fuertes incrustaciones generales (como OpenAI o E5) y luego se ajustan en texto específico del dominio.
Desde el punto de vista del rendimiento, la latencia de los modelos varía. Los modelos más pequeños (p. ej., E5-base-768) son más rápidos en la inferencia, mientras que los modelos propietarios grandes (3072D de OpenAI) son más lentos y pueden permitir solo una solicitud a la vez. Si el hardware local es limitado, se pueden utilizar modelos más pequeños o cuantificados. La licencia es importante: OpenAI y Cohere cobran por solicitud y tienen políticas de uso, mientras que los modelos abiertos como E5/GTE o BGE de Google (abierto mediante VertexAI con cuotas) evitan los costes de API. En resumen, cualquier base de datos vectorial puede ingerir incrustaciones de cualquiera de estos modelos, pero los arquitectos deben considerar la dimensionalidad de la incrustación, el coste, la compatibilidad multilingüe y la adecuación al dominio al seleccionar modelos para datos de aviación.
Tipos de bases de datos vectoriales
Existe una variedad de sistemas de bases de datos vectoriales, desde bibliotecas livianas hasta plataformas completas:
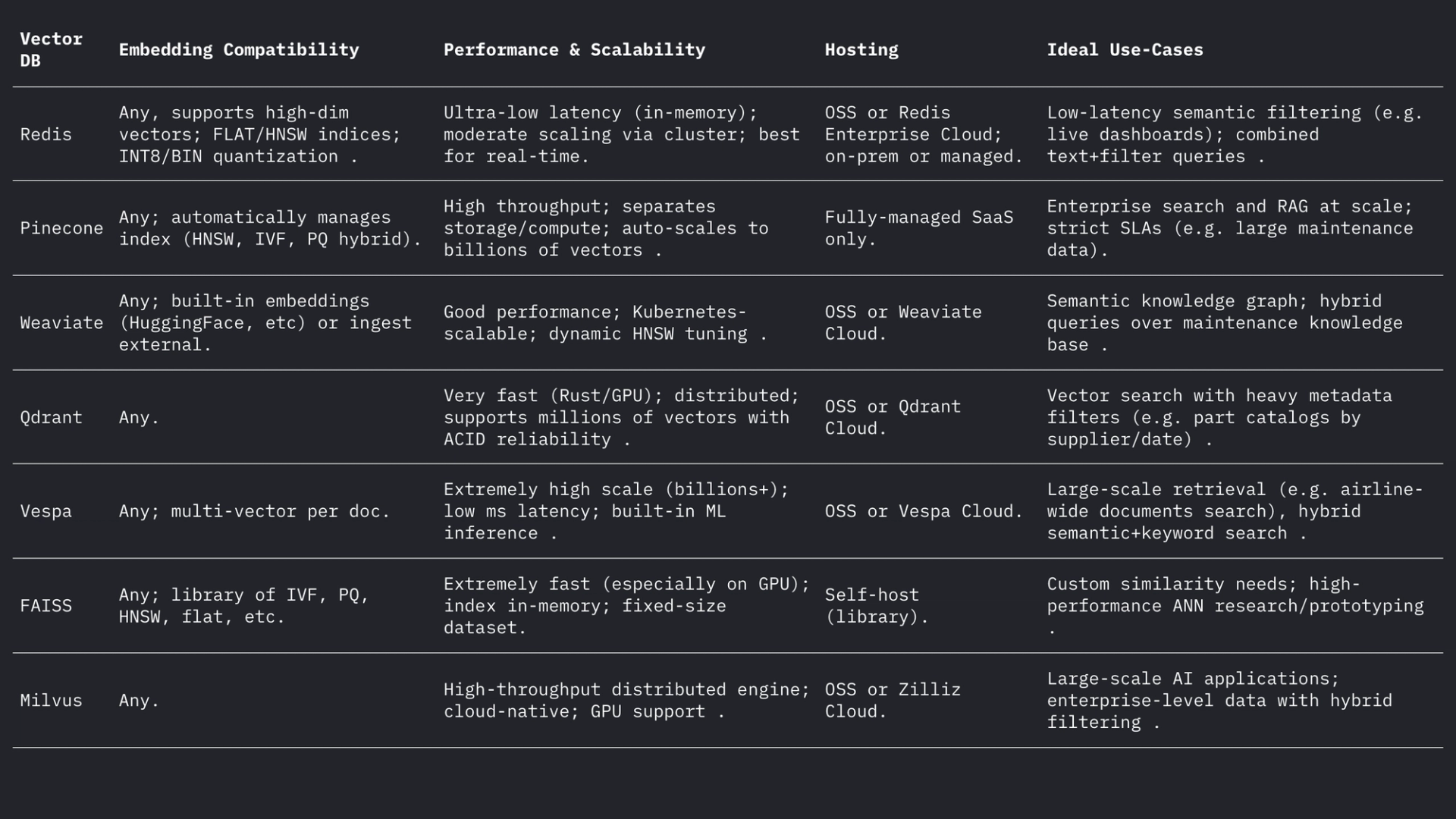
- Redis (Conjuntos de vectores): Redis es un almacén de valores clave en memoria con un módulo de índice vectorial. Admite índices FLAT (fuerza bruta exacta) y HNSW. Los conjuntos de vectores de Redis permiten actualizaciones dinámicas de forma única: los gráficos HNSW se mantienen bidireccionalmente para que los vectores se puedan agregar o eliminar sobre la marcha con efecto inmediato. Redis admite la cuantificación (8 bits o binaria) para reducir la memoria (hasta 4×–32×) con una pérdida mínima de precisión. También proporciona filtrado híbrido: los vectores se pueden almacenar junto con etiquetas de texto o campos numéricos y filtrar (p. ej., .year > 2020) en la misma consulta. Como motor en memoria, Redis ofrece una latencia ultrabaja a costa del uso de RAM. Escala horizontalmente mediante la agrupación en clústeres, aunque los tamaños de los clústeres suelen ser menores que los de las plataformas vectoriales dedicadas. Redis está disponible como código abierto o a través de Redis Enterprise Cloud.
- Pinecone: un servicio en la nube de búsqueda vectorial totalmente gestionado. Pinecone elimina toda la infraestructura: separa el almacenamiento del procesamiento y escala a miles de millones de vectores, manteniendo tiempos de consulta rápidos. Gestiona automáticamente los índices de forma interna (combinando HNSW, IVF, PQ, etc.) para un rendimiento óptimo. La desventaja es el coste y la opacidad: Pinecone es fácil de usar (sin operaciones), pero más caro que OSS. Destaca en cargas de trabajo de alto rendimiento y sujetas a SLA, y admite consultas híbridas (palabras clave + vectores) y funciones empresariales. Pinecone es ideal para equipos que necesitan escalabilidad y fiabilidad de nivel empresarial sin necesidad de gestionar servidores.
- Weaviate: una base de datos vectorial centrada en grafos de código abierto (también disponible como servicio gestionado). Weaviate permite la estructuración de esquemas y grafos de conocimiento enriquecidos junto con vectores. Ofrece una API GraphQL para combinar la búsqueda semántica de vectores con consultas tradicionales (recuperación híbrida). Weaviate utiliza principalmente índices HNSW (y puede usar índices planos para conjuntos de datos pequeños). Ajusta automáticamente los parámetros de búsqueda o permite la indexación asíncrona para optimizar el rendimiento. Con módulos para aprendizaje profundo, Weaviate puede incluso generar vectores (p. ej., mediante modelos HuggingFace). Escala mediante Kubernetes y clústeres en la nube o locales. Las fortalezas de Weaviate son la búsqueda híbrida semántica y simbólica y la flexibilidad en el modelado de datos; es adecuado cuando las relaciones (p. ej., jerarquías de piezas a aeronaves) son tan importantes como la similitud vectorial.
- Qdrant: un motor de búsqueda vectorial de código abierto en Rust. Qdrant ofrece un índice ANN de alto rendimiento con un completo filtrado de metadatos. Admite índices HNSW con escalado automático dinámico y proporciona una API HTTP. Cabe destacar que Qdrant se centra en un filtrado riguroso y la fiabilidad: admite la implementación distribuida, transacciones ACID y aceleración por GPU. Ofrece un excelente rendimiento con grandes conjuntos de datos y ofrece una alta tasa de recuperación. Qdrant Cloud simplifica la implementación, pero es igualmente robusto en su versión autoalojada. Esto convierte a Qdrant en una excelente opción cuando se necesita combinar similitud vectorial y filtros estructurados (por ejemplo, buscar solo dentro de ciertos modelos de aeronaves o rangos de fechas).
- Vespa: un motor de búsqueda y análisis de código abierto, originario de Yahoo. Vespa integra de forma única la búsqueda vectorial con la búsqueda clásica de índice invertido. Puede gestionar miles de millones de vectores con un rendimiento excepcional: la plataforma anuncia compatibilidad con miles de QPS con latencias inferiores a 100 ms sobre grandes volúmenes de datos. Vespa admite la búsqueda multivectorial por documento y la búsqueda híbrida (semántica y por palabra clave). Su indexación ANN incluye HNSW (y variantes novedosas como HNSW-IF, que combinan el filtrado de archivos invertidos). Como servidor de aplicaciones completo, Vespa también admite modelos de clasificación personalizados y canales de inferencia de aprendizaje automático (ML). Por lo tanto, es ideal para aplicaciones de búsqueda a gran escala y de misión crítica (p. ej., portales de búsqueda para aerolíneas) donde se requiere escalabilidad y relevancia híbrida. Vespa puede autogestionarse o utilizarse a través de Vespa Cloud.
- FAISS: una biblioteca de grado de investigación de Meta para la búsqueda de similitud. FAISS no es una base de datos independiente, sino una colección de índices altamente optimizados (Flat, IVF, PQ, HNSW, etc.) que se ejecutan en CPU/GPU. Alcanza una velocidad excepcional (especialmente con GPU) y flexibilidad: se puede utilizar casi cualquier métrica de distancia o método de indexación. Sin embargo, FAISS no incluye un motor de almacenamiento/consulta ni filtrado de metadatos; debe integrarlo en su propio sistema. Es más adecuado cuando se necesita el máximo rendimiento y control sobre los algoritmos de indexación. Por ejemplo, FAISS se usa ampliamente en la investigación de visión artificial y aprendizaje automático, donde la recuperación y la velocidad son primordiales y los tamaños de los datos son fijos. En aviación, FAISS podría respaldar una herramienta de búsqueda personalizada para incrustaciones de muy alta dimensión (p. ej., reconocimiento de piezas basado en imágenes), pero requiere una arquitectura circundante.
- Milvus: una popular base de datos vectorial de código abierto diseñada para cargas de trabajo a gran escala. Milvus ofrece modos independientes y distribuidos, y admite miles de millones de vectores con una alta consistencia. Proporciona múltiples tipos de índices (HNSW, IVF, Annoy, etc.) y métricas (coseno, L2, etc.), además de búsqueda híbrida mediante filtrado escalar. Milvus está acelerado por GPU y es nativo de la nube (se integra con Kubernetes). Incluye funciones empresariales como instantáneas y cifrado, y Zilliz lo desarrolla activamente. La arquitectura de Milvus está diseñada para la escalabilidad y el rendimiento, lo que la hace ideal para aplicaciones con uso intensivo de datos, como el análisis de archivos masivos de manuales o registros de sensores. Zilliz también ofrece Milvus Cloud para alojamiento gestionado.
Cada uno de estos sistemas gestiona vectores y filtros de forma diferente, pero todos admiten distancias L2, producto interno (punto) y coseno (a menudo almacenando vectores normalizados). El foro de Weaviate indica que puede almacenar vectores de hasta 65535 dimensiones, muy por encima de los tamaños de incrustación habituales, lo que demuestra la flexibilidad de los motores modernos. En resumen:
Casos de uso en la aviación
Búsqueda semántica: El mantenimiento de aeronaves implica el uso de extensas colecciones de manuales, boletines de servicio y documentos normativos. Un sistema de búsqueda vectorial permite a los ingenieros realizar consultas en lenguaje natural (o incluso por voz) y recuperar pasajes o documentos relevantes semánticamente. Por ejemplo, en lugar de una búsqueda por palabra clave como "fuga de aceite de motor", una búsqueda integrada puede encontrar párrafos de boletines que describen "fuga de fluido hidráulico" si el contexto es similar. Como demostró Infosys/AWS, almacenar cada documento técnico como vectores permite a los agentes con tecnología LLM responder a las consultas de mantenimiento recuperando los documentos más relevantes del repositorio.
Coincidencia difusa de piezas: Las piezas de aviación suelen tener identificadores crípticos (NSN o números de pieza) y nombres descriptivos que varían según el proveedor. La incrustación vectorial de las descripciones de las piezas, o incluso de los números de pieza (tratados como texto), puede revelar casi duplicados que la coincidencia basada en reglas no detecta. En otros ámbitos, se han utilizado incrustaciones de palabras para la coincidencia semántica de nombres; de forma similar, la incrustación de descriptores de piezas permite encontrar la pieza con su descripción más cercana en los catálogos de proveedores, incluso si la ortografía o los códigos difieren. Esto podría unificar el inventario de múltiples fuentes.
Clasificación y agrupación de registros: Los registros de reparaciones y fallos suelen ser texto libre. Los modelos de incrustación pueden convertir las entradas de registro en vectores, y la agrupación de estos vectores permite agrupar automáticamente patrones de fallo similares. Por ejemplo, el marco "HELP" agrupa los registros del sistema en tiempo real según sus incrustaciones para descubrir plantillas de registro recurrentes. En aviación, la agrupación análoga podría identificar modos de fallo comunes o categorizar las entradas de mantenimiento no programado sin etiquetas predefinidas, lo que permite el análisis de problemas frecuentes (p. ej., agrupar incidentes de "vibración extraña"). Esta agrupación semántica no supervisada facilita el análisis de tendencias y la predicción de la carga de trabajo.
Recuperación Conversacional (RAG): Las incrustaciones sustentan los sistemas de Generación Aumentada por Recuperación (RAG) que impulsan los chatbots sobre documentos. Un ejemplo de chatbot en PDF muestra la arquitectura: extraer texto de los manuales, fragmentarlo, incrustar cada fragmento y almacenarlo en un almacén vectorial (como FAISS). En tiempo de ejecución, cada consulta del usuario se incrusta y se utiliza para recuperar los k fragmentos relevantes principales a través del índice vectorial. Estos fragmentos forman el contexto para que un LLM responda la pregunta. En el ámbito de la aviación, una canalización RAG permite a un técnico "chatear" con el gemelo digital de la aeronave: por ejemplo, preguntar "¿Cuál es el procedimiento para reemplazar el interruptor de calor del tubo de Pitot?" y obtener una respuesta precisa extraída de los manuales del fabricante del equipo original (OEM).
Indexación Predictiva de Fallas: Los registros históricos de mantenimiento describen las fallas y sus correcciones. Se podrían indexar las descripciones de las fallas como vectores para que la descripción de un nuevo incidente coincida con casos anteriores similares. Investigaciones en mantenimiento predictivo han demostrado que calcular la similitud semántica del texto de falla mediante incrustaciones de transformadores (con similitud de coseno o Pearson) permite agrupar con éxito las fallas relacionadas. En la práctica, cuando un mecánico registra una nueva descripción de falla, el sistema podría recuperar incidentes pasados con alta similitud de incrustación para sugerir posibles causas raíz o verificaciones, realizando una predicción eficaz basada en la proximidad en el espacio de incrustación.
Consideraciones prácticas de diseño
Dimensionalidad de la incrustación: Las incrustaciones de mayor dimensión capturan más matices, pero cuestan más en almacenamiento y computación. Las opciones comunes son 768, 1024, 1536 o 3072 dimensiones. Por ejemplo, los modelos más grandes de OpenAI usan 1536–3072 dimensiones, mientras que la base E5/GTE de Meta usa 768 o 1024. En un experimento piloto, indexar el mismo corpus tomó 2,4 veces más tiempo con incrustaciones de 1536D que con 768D. Por lo tanto, si el rendimiento y la latencia son críticos (p. ej., filtrado en el dispositivo de cientos de consultas/seg), 768D o 1024D pueden ser suficientes. Si la recuperación máxima es el objetivo (y el hardware lo permite), las dimensiones más grandes son aceptables. Para la aviación, se podría comenzar con 1024D (equilibrado) y probar modelos más pequeños frente a más grandes en tareas de recuperación en datos de dominio.
Métrica de distancia: La elección del coseno (o producto escalar normalizado) frente al euclidiano puro depende de la incrustación. La mayoría de las incrustaciones de texto modernas se comparan mediante la similitud del coseno. Por ejemplo, Tekgöz et al. descubrieron que las métricas de coseno/Pearson ofrecían la mejor similitud para las descripciones de fallos. Redis y otras empresas admiten la especificación explícita de "COSINO" (normalización de vectores en segundo plano), mientras que muchos sistemas utilizan el producto interno en vectores prenormalizados. En la práctica, el coseno y el producto interno son equivalentes si las incrustaciones están normalizadas. La distancia euclidiana es menos común para el texto, pero conceptualmente similar cuando los vectores están en una esfera. Recomendación: utilizar el coseno para incrustaciones basadas en texto.
Metadatos y estructuración híbrida: es importante almacenar incrustaciones de vectores junto con metadatos estructurados (modelo de aeronave, capítulo ATA, fecha, número de pieza, etc.) para una búsqueda refinada. Todos los almacenes de vectores modernos permiten adjuntar metadatos a cada vector. Por ejemplo, Redis Vector Sets le permite filtrar por atributos JSON en la misma consulta (p. ej., WHERE aircraft_model = 'A320' AND ATA = '21'). Qdrant proporciona un potente filtrado booleano para restringir los resultados de vectores por metadatos. Al diseñar el esquema, defina los campos de metadatos (p. ej., modelo, ata, fecha, part_no) e indexelos normalmente mientras marca el campo de texto como VECTOR. En las consultas híbridas, el sistema primero aplica el filtro de metadatos (o lo combina a través de una penalización de puntuación) y luego busca solo el subconjunto de vecinos más cercanos, lo que mejora la precisión. Asegúrese de que los filtros críticos (p. ej., número de cola de la aeronave o rango de tiempo) estén en campos escalares indexados para aprovechar el filtrado de la base de datos.
Ajuste de latencia y rendimiento: Los parámetros del índice ANN deben ajustarse para la latencia objetivo. Para HNSW, aumentar el parámetro efSearch produce una mayor recuperación, pero aumenta linealmente el tiempo de consulta. Un enfoque práctico es comparar la recuperación frente a la latencia en un conjunto retenido: comience con un ef bajo para la velocidad, luego increméntelo hasta que la recuperación se estabilice. Weaviate incluso admite un "ef dinámico" que escala ef con el recuento de resultados deseado. Para cargas de trabajo por lotes, se pueden usar índices FLAT (exactos) para maximizar la precisión, mientras que para consultas en tiempo real de decenas de milisegundos, es mejor HNSW o IVF con parámetros ajustados. La cuantificación (8 bits, cuantificación del producto) es otra palanca: p. ej., las configuraciones Q8 vs BIN de Redis reducen drásticamente la memoria y aceleran la búsqueda, a expensas de una ligera caída en la precisión.
Actualizaciones del índice: Si sus datos cambian con frecuencia (nuevas entradas de registro o actualizaciones manuales), elija sistemas que admitan la indexación dinámica. La implementación de HNSW de Redis permite inserciones y eliminaciones sobre la marcha sin tener que reconstruir el índice. Weaviate puede actualizar HNSW de forma asíncrona (para que las escrituras no bloqueen las lecturas). Otros sistemas, como FAISS, suelen requerir reindexación, así que úselos para corpus mayoritariamente estáticos. Planifique la reindexación si llegan nuevos manuales o si es necesario añadir registros diarios. En muchos sistemas de aviación, los manuales cambian lentamente, pero llegan entradas diarias de registros/despachos, por lo que los enfoques híbridos (escribir nuevos vectores en un índice activo durante un día y fusionarlos cada noche) pueden funcionar.
Resumen
Las bases de datos vectoriales y los modelos de incrustación, en conjunto, permiten una inteligencia semántica completa sobre los datos de aviación. Las incrustaciones de alta calidad (p. ej., los modelos 768–3072D) traducen manuales, registros y descripciones de piezas en vectores con capacidad de búsqueda, mientras que los almacenes de vectores especializados (Redis, Pinecone, Weaviate, Qdrant, Vespa, FAISS, Milvus) proporcionan los índices de ANN y el filtrado necesarios a gran escala. La tabla anterior compara las características clave: Redis y Qdrant destacan por su baja latencia con filtrado; Pinecone y Milvus brillan a gran escala; Weaviate y Vespa admiten consultas híbridas (gráfico+vector); FAISS ofrece el máximo rendimiento para pipelines personalizados. Las opciones de incrustación (modelo, dimensión, normalización) y el ajuste de índices (parámetros HNSW, cuantificación) deben equilibrarse entre la recuperación y la velocidad. En conjunto, estas tecnologías permiten a los equipos de ML de aviación crear herramientas avanzadas (IU de búsqueda semántica, chatbots de mantenimiento, análisis predictivos) que convierten registros y manuales no estructurados en información procesable.
Tendencias de mantenimiento de aviación que podrían cobrar impulso en circunstancias inciertas
Las aeronaves permanecen en servicio durante más tiempo, las cadenas de suministro son un polvorín y la tecnología evoluciona de la noche a la mañana. Descubra las tendencias de mantenimiento que cobran impulso y lo que significan para los operadores que buscan mantenerse en el aire y ser rentables.

July 16, 2025
Comprender el vínculo entre la aviación y los aranceles: impacto y soluciones alternativas
Los aranceles están afectando duramente a la aviación estadounidense, y la industria está contraatacando. Así es como las aerolíneas están encontrando lagunas, adaptándose y reduciendo costos, y por qué la IA y el ERP podrían ser clave para mantener su resiliencia.

July 15, 2025
Portal de la cadena de suministro. Un vendedor. Múltiples compradores. Control total.
El portal Aviation Supply Chain Portal es esencialmente una plataforma privada de comercio electrónico diseñada a medida para proveedores de aviación y sus clientes. Diseñado exclusivamente para aerolíneas, MRO y distribuidores de piezas, centraliza el inventario, las compras y la colaboración de proveedores en un sistema seguro. En la práctica, un OEM o distribuidor de piezas "marca blanca" este portal e invita a sus compradores aprobados (aerolíneas, MRO, etc.) a iniciar sesión. Estos compradores ven un catálogo completo de piezas (sincronizado en tiempo real desde el ERP del vendedor) y pueden buscar, filtrar y comparar artículos tal como lo harían en un gran mercado en línea. Sin embargo, a diferencia de los intercambios públicos abiertos, este portal es privado: solo el proveedor (con muchos compradores) está en la plataforma, lo que le da a la empresa control total sobre precios, existencias y acceso de usuarios.

July 13, 2025
Cómo ePlaneAI está revolucionando las adquisiciones de aviación con blockchain
Las piezas falsificadas están dejando en tierra las flotas. ePlaneAI está cambiando eso con el aprovisionamiento basado en blockchain, aportando trazabilidad, confianza y automatización a la aviación.
